Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao
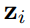 為 implicit representation,為常數張量(tensor)的集合
為 implicit representation,為常數張量(tensor)的集合 。
。
不同的任務或是mult-head的神經網路輸入資料的特徵空間可能因不同任務而不一致,因此需要進行平移旋轉等操作進行對齊。
常見公式為: 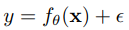 ,目標是要讓預測結果與正確解答間的差異能夠越小越好
,目標是要讓預測結果與正確解答間的差異能夠越小越好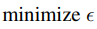 ,相當於讓相同任務目標的解能夠匯聚在同一個點上,但是此作法只能處理單一任務。
,相當於讓相同任務目標的解能夠匯聚在同一個點上,但是此作法只能處理單一任務。
為了實現多任務,要讓每個任務在同一時刻manifold空間都盡可能找到解答,但這樣的方法很難利用簡單的數學公式替每個任務進行求解。
因此提出一個error term方法
整合Explicit Knowledge以及Implicit Knowledge的方法。
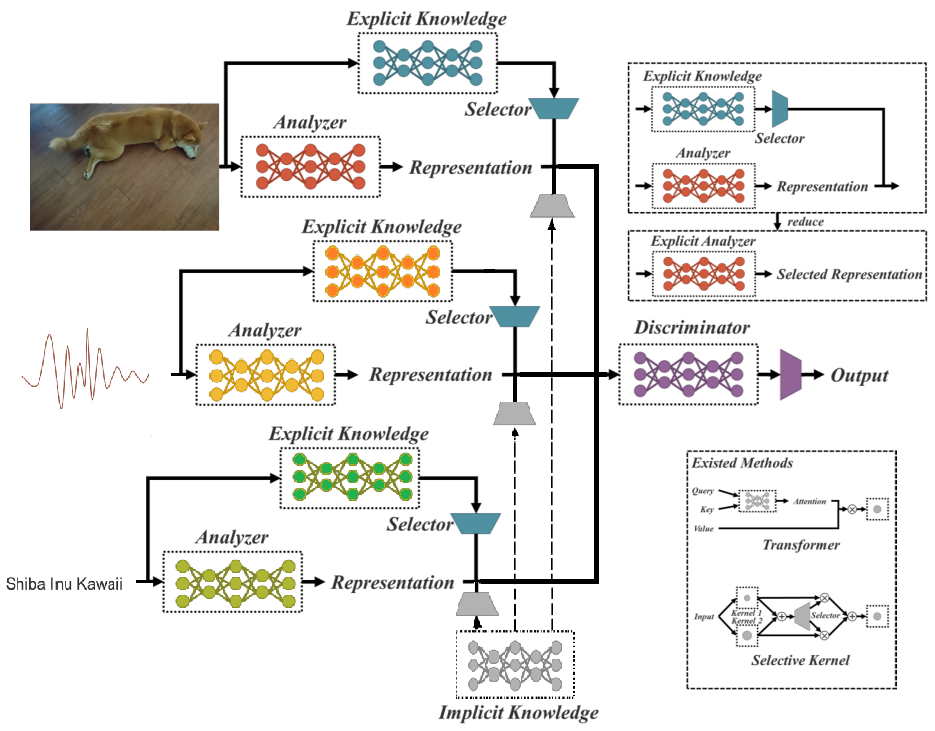
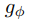 依照任務選取或是組合explicit以及implicit knowledge的操作。
依照任務選取或是組合explicit以及implicit knowledge的操作。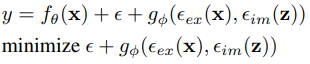
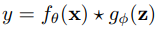 ,
, 代表結合
代表結合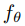 以及
以及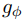 的操作(相加、相乘、concatenation)。
的操作(相加、相乘、concatenation)。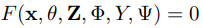
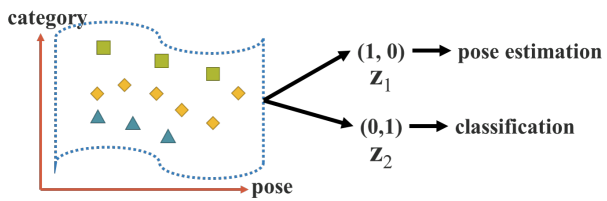
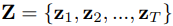 不同任務T對應的implicit latent code。
不同任務T對應的implicit latent code。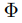 ,用以從z提取出implicit representation的超參數。
,用以從z提取出implicit representation的超參數。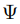 ,計算最終輸出的超參數。
,計算最終輸出的超參數。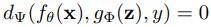
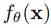 。
。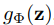 。
。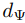 ,完成不同的任務。
,完成不同的任務。Dataset採用: MSCOCO
要解決的任務: 物件偵測、實例分割、全景分割(panoptic segmentation)、關鍵點偵測、物件分割(stuff segmentation)、圖片敘述(image caption)、多標註物件分類、長尾分布辨識(
long tail object recognition)。
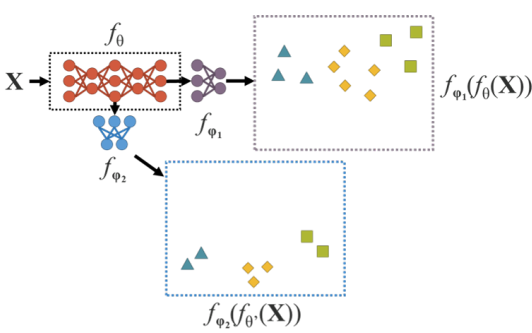
以YOLOv4為Backbone,引入implicit knowledge進去模型:
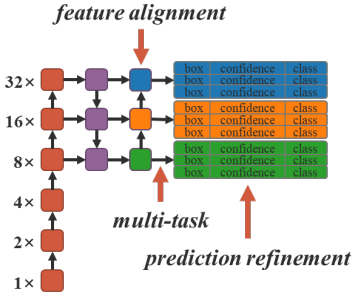
Feature alignment:
Prediction refinement:
沒加此技術,模型仍然可以完成原有的物件偵測任務。
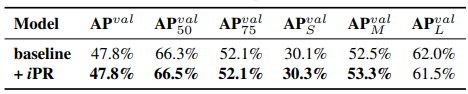
多任務:
如果只是將多目標的任務的loss設計在一起,這樣會讓整個模型效能下降,甚至比不上將不同模型分開訓練後整合在一起的結果。
因此引入implicit representation進去實現多任務:
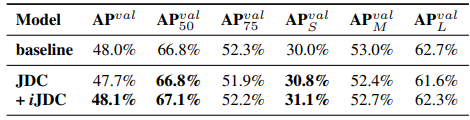
Implicit representation與explicit representation的結合方式:
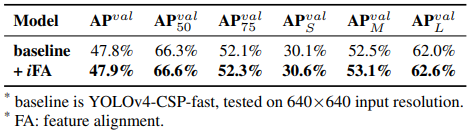
實驗做了feature alignment以及prediction refinement。
Feature alignment:
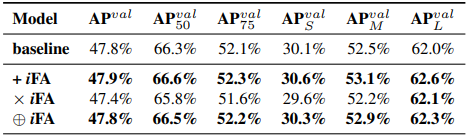
Prediction refinement: 相乘比相加好,但沒比較concatenation,因為concate後的輸出維度會變。
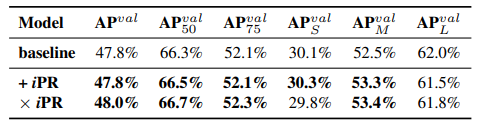
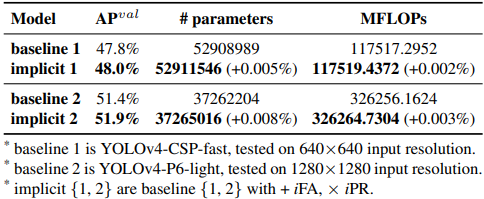
參數量、FLOPs:
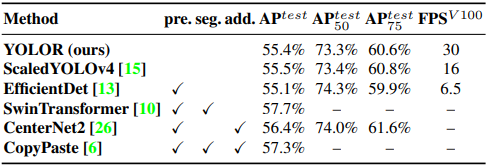
跟其他方法的比較:
不用增加額外的訓練資料或是標註檔案,並且可以達到與當時最好方法差不多的效果。


 iThome鐵人賽
iThome鐵人賽